
Model-driven observability: Embedded Alert Rules
by Michele Mancioppi on 17 September 2021
This post is about alert rules. Operators should ensure a baseline of observability for the software they operate. In this blog post, we cover Prometheus alert rules, how they work, and their gotchas, and discuss how Prometheus alert rules can be embedded in Juju charms and how Juju topology enables the scoping of embedded alert rules to avoid inaccuracies.
In the first post of this series, we covered the general idea and benefits of model-driven observability with Juju. In the second post, we dived into the Juju topology and its benefits with respect to entity stability and metrics continuity. In the third post, we discussed how the Juju topology enables the grouping and management of alerts, helps prevent alert storms, and how that relates to SRE practices.
The running example
In the remainder of this post, we will use the following example:
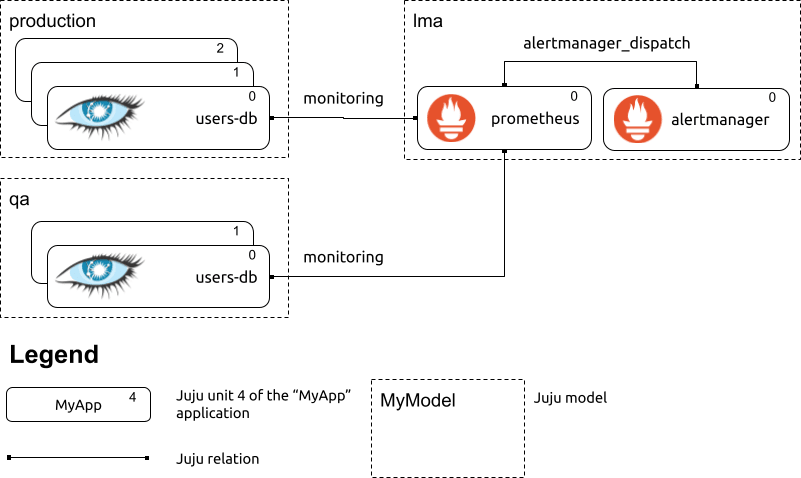
A depiction of three related Juju models: “lma”, “production” and “qa”. The “lma” model contains the monitoring processes; the “production” and “qa” models contain each one “users-db” Juju application, consisting of one Cassandra cluster. Both Cassandra clusters are monitored by Prometheus deployed in the “lma” model.
In the example above, the “monitoring” relations between Prometheus and the two Cassandra clusters, each residing in a different model, result in Prometheus scraping the metrics endpoint provided by the Cassandra nodes. The cassandra-k8s charm, when related to a Prometheus charm over the “monitoring” relation, automatically sets up Instaclustr’s Cassandra Exporter on all cluster nodes. The resulting metrics endpoints are scraped by Prometheus without any manual intervention by the Juju administrator.
Prometheus alert rules
When monitoring systems using Prometheus, alert rules define anomalous situations that should trigger alerts. Below is an example of a typical alert rule definition:
alert: PrometheusTargetMissing
expr: up == 0
for: 0m
labels:
severity: critical
annotations:
summary: Prometheus target missing (instance {{ $labels.instance }})
description: "A Prometheus target has disappeared."The rule above is adapted from the very excellent Awesome Prometheus alerts, which provides libraries of alert rules for a variety of technologies that can be monitored with Prometheus.
Alert rule ingredients
There are a few key parts to an alert rule:
- The value of the “alert” field is the identifier (also known as “alertname”) of the alert rule.
- The “expr” field specifies a PromQL query; in the example above, the query is straightforward: it looks for values of the built-in “up” timeseries, that Prometheus fills with “1” when successfully scraping a target, and “0” when the scraping fails.
- The “for” field specifies a grace period, that is, a time duration over which the PromQL query at “expr” must consistently evaluate as false before the alert is fired. The default of the “for” field is zero, which means that the alert will be fired as soon as the PromQL query fails; it is good practice to choose a less ‘twitchy’ value than this for most alerts. Overall, the goal is to strike a good trade-off between detecting issues as soon as possible, and avoiding false positives resulting from flukes or transient failures.
- The “label” and “annotation” fields allow you to specify metadata for the alerts, like their “severity”, “summary”, and “description”. None of the labels or annotations are actually required, but are indeed customary in many setups. And if you are pondering the difference between labels and annotations, it is precisely like in Kubernetes: labels are meant to be machine-readable, annotations are for informing people. You can use labels with the built-in templating language for alert rules to generate the values of annotations, as well as specifying matchers in Alertmanager routes to decide how to process those alerts.
Gotchas when specifying alert rules
There are a few things to watch out for when specifying alert rules.
Metadata consistency is key
I have already mentioned the need for consistency in your labels and annotations, with specific emphasis on the way you specify the severity of an alert. Please do not get inspired by the chaos that is “severity levels” in logging libraries (especially prevalent in the Java ecosystem). Rather, use whatever model for incident severity is defined in your operational procedures.
Scoping
Another big, and maybe bigger gotcha is how you scope your alert rules. In the example above we have conspicuously omitted a very important ingredient to a PromQL query: label filters. Label filters allow you to select which specific timeseries are going to be evaluated for the rule by Prometheus across all timeseries with the same name, in our case “up”. That is, the alert rule we used as an example will trigger separately for any timeseries named “up” with a value of “0” and generate a separate, critical alert! This is likely not optimal: after all, not all systems are equally important, and you should be woken up at night during your rotations only when genuinely important systems are having issues. (Remember what we discussed about alert fatigue in another post!)
Assuming that your Prometheus is monitoring both production and non-production workloads, and that the “environment” label contains the identifier of the deployment, the following might be a better alert rule:
alert: PrometheusTargetMissing
expr: up{environment="production"} == 0
for: 0m
labels:
severity: critical
annotations:
summary: Prometheus target missing in production (instance {{ $labels.instance }})
description: "A Prometheus target has disappeared from a production deployment."By filtering the “up” timeseries to those with the label “environment” matching “production”, alert rules with critical severity will be issued only for timeseries collected from production systems, rather than all of them. (By the way, if you have multiple production deployments, PromQL has a handy regexp-based matching of labels via the “=~” operator.)
Sensitivity
Notice how, in the previous section, the revised alert rule still uses the value “0m” for the for key. That means that as soon as the Prometheus scraping has a hiccup, an alert is fired. Prometheus scraping occurs over networks, and the occasional fluke is pretty much a given. Moreover, depending on how you configure Prometheus’ scrape targets, there may be lag between your workloads being decommissioned, and Prometheus ceasing to scrape them, which is a strong source of false positives when alert rules are too sensitive.
Over-sensitivity of alert rules is what the “for” keyword is for, but figuring out the right value is non-trivial. In general, you should select the value of “for” to be:
- Not higher than the maximum amount of time you can tolerate for an issue to go undiscovered, which very much relates to the targets you have defined (e.g. for your Service Level Objectives).
- Not lower than two or three times the frequency of the scraping job that produces those timeseries.
The minimum tolerance for an alert rule is very interesting. Prometheus scrapes targets for metrics values with a frequency that is specified on the scrape job, with default of one minute. Similarly to the way the Nyquist–Shannon sampling theorem creates a link between sampling continuous signals without losing information, you should not define an alert rule duration that is too close to the sampling interval of the scrape jobs it relies on. Depending on the workload of Prometheus, and how quickly the scraping is executed (after all, it’s an HTTP call that is served by most Prometheus endpoints synchronously), you are all but guaranteed to have variability in the time interval between two successive data points in a given Prometheus timeseries. As such, you need a tolerance margin built-in to your “for” setting. A good rule of thumb is to have the value of “for” to be two to three times higher than the maximum scrape interval of the scrape jobs producing the relevant timeseries.
Embedding alert rules in Juju charms
The Prometheus charm library provides easy-to-integrate means for charm authors to expose the metrics endpoints provided by applications to the Prometheus charm. Similarly, adding alert rules to a charm is as easy as adding “rule files” to a folder in your charm source code (cf. the cassandra-operator repository).
There are two interesting aspects to be discussed about alert rules embedded in charms: how to scope them and the nature of the issues that are meant to be detected by those alert rules.
Scoping of embedded alert rules
As discussed in the section about alert scoping, it is fundamental to correctly restrict which systems are monitored by which alert rules, which in Prometheus is achieved by applying label filters to the alert rule expression based on the time-series labels.
When monitoring software that is operated by Juju, the Juju topology provides just what we need to ensure that alert rules embedded in a charm apply separately to each single deployment of that charm. The Juju topology is a set of labels for telemetry (and alert rules!) that uniquely identifies each instance of a workload operated by Juju. All it takes to leverage the Juju topology with alert rules, is writing the alert rule adding the %%juju_topology%% token in the label filter for the timeseries:
alert: PrometheusTargetMissing
expr: up{%%juju_topology%%} == 0
for: 0m
labels:
severity: critical
annotations:
summary: Prometheus target missing in production (instance {{ $labels.instance }})
description: "A Prometheus target has disappeared from a production deployment."At runtime, the Prometheus charm replaces the %%juju_topology%% token with the actual juju topology of the system, like the following:
alert: PrometheusTargetMissing
expr: up{juju_application="user-db",juju_model="production",juju_model_uuid="75fcb386-daa0-4681-8b4d-786481381ee2"
} == 0
for: 0m
labels:
severity: critical
annotations:
summary: Prometheus target missing in production (instance {{ $labels.instance }})
description: "A Prometheus target has disappeared from a production deployment."Having all the Juju topology labels reliably added to your alert rules ensures that there is a separate instance of the alert rule for every deployment of the charm, and those rules are evaluated in isolation for each deployment.
There is no possibility that your alert rule will mix data across different deployments and, in so doing, cause false positives or negatives. Besides, something we are looking at is actually entirely automating the injection of the Juju topology in the time series queried by embedded alert rules, eliminating the need to add the %%juju_topology%%.
While this is not particularly easy to achieve (it requires a parser for PromQL, a lexer, and a bunch of other machinery), this is going to be an iterative improvement we are very much looking forward to, as it eliminates the risk of charm authors shipping incorrectly-scoped alert rules.
Nature of embedded alert rules
When embedding alerts in a charm, the author will almost certainly specify rules aiming at detecting failure modes of the software operated by the charm. For example, in the Cassandra charm, we embed rules for detecting write and read failures of requests, or issues with compaction (a process Cassandra uses to optimize the use of storage and memory dropping, for example, outdated data).
According to the categorization of alerts described in “My Philosophy on Alerting” by Rob Ewaschuk, such alert rules are “cause-based alerts”. Cause-based alerts can be noisy, mostly because they tend to be redundant, with multiple alert rules triggered by the same issue. For example, an undersized CPU can make Cassandra sad in many different ways all at once. However, cause-based alerts also allow you to quickly identify the source of issues, especially if you are aware of what impacts various types of issues have on your end users (“when the users-db database is down, users trying to log will see errors”).
Of course, model-driven observability with Juju needs a way of specifying “symptom-based”, that is, detecting issues that directly impact and are visible to end-users. However, those alerts are not something that a charm author can embed in a charm, but rather are the responsibility of the Juju administrators, as the kind of alert rules one must specify depend on the overall architecture of the applications operated by Juju. We will come back to this topic in a future post.
What’s next
In this blog post I covered the basics of alerting with Prometheus, how Juju charm authors can embed alert rules within their charms, and how the Juju topology enables the scoping of these alert rules to single Juju applications, avoiding one of the pitfalls of writing alert rules. The following installments of this series will cover:
- The benefits of Juju topology for Grafana dashboards
- How to bundle Grafana Dashboards with your charms, and let Juju administrators import them in their Grafana deployments with one Juju relation
- How Juju administrators can specify alert rules, which enables them to set up symptom-based monitoring for Juju-operated applications
Meanwhile, you could start charming your applications running on Kubernetes. Also, have a look at the various charms available today for a variety of applications.
Other posts in this series
- Part 1: Modern monitoring with Juju
- Part 2: The magic of Juju topology for metrics
- Part 3: Taming alert storms
If you liked this post…
Find out about other observability workstreams at Canonical!
Also, Canonical recently joined up with renowned experts from AWS, Google, Cloudbees, and others to analyze the outcome of a comprehensive survey administered to more than 1200 KubeCon respondents. The resulting insightful report on the usage of cloud-native technologies is available here: Kubernetes and cloud native operations report 2021.